Nuova architettura VLIW-4
Sin dalla serie R600 ATI ha introdotto la nuova architettura a shader unificati, che ha costituito una rivoluzione rispetto alle precedenti generazioni di schede video, caratterizzate da shader separati per vertici, geometria e pixel. Grazie agli shader unificati è ormai possibile processare indistintamente le varie parti del processo di renderizzazione 3D, permettendo una migliore distribuzione delle risorse e aumentando notevolmente l’efficienza computazionale. L’unità basilare di computazione finora utilizzata (thread processor) è caratterizzata da 5 unità elaborative (ALU o Stream Processor) comandate da una istruzione complessa in grado di accogliere fino a 6 comandi di cui 5 dedicati alle operazioni matematiche e uno dedicato alla gestione delle interruzioni (branch unit). Tale parola di comando è caratteristica delle architetture Very Long Instruction Word (VLIW) e caratterizza, ormai da qualche tempo, le GPU AMD.
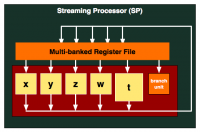
Peculiarità della precedente generazione architetturale è l’utilizzo di un core caratterizzato da 5 ALU distinte (VLIW 5), di cui 4 più semplici e una più complessa, in grado di effettuare calcoli trascendentali come quelli sulle funzioni seno e coseno. Con il passare degli anni e dell’evoluzione dei giochi, gli ingegneri AMD si sono resi conto che questa unità complessa (chiamata anche T-unit) causa dei rallentamenti sull’intero thread processor. Essendo l’unità più complessa, può accadere, infatti, che l’esecuzione delle sue istruzioni sia più lenta rispetto a quella delle altre unità più semplici che devono attendere la T-unit senza poter eseguire altri calcoli.
Con la serie Cayman, AMD ha ristrutturato il thread processor utilizzando 4 unità general purpose, ovvero con stesse capacità elaborative. In questo modo il core è stato semplificato utilizzando unità tutte uguali, come pure sono stati semplificati i registri e le unità di scheduling delle istruzioni. Utilizzando stream processor tutti uguali non ci saranno più unità in stallo per l’attesa dell’altra più lenta. Ovviamente i calcoli complessi potranno essere sempre eseguiti, ma in questo caso utilizzeranno 3 delle 4 ALU generiche, sfruttando in maniera ottimale tutte le risorse a disposizione. Grazie a questa semplificazione, AMD dichiara un miglioramento delle performance per unità di area del 10%; il tutto mantenendo invariato il processo produttivo.
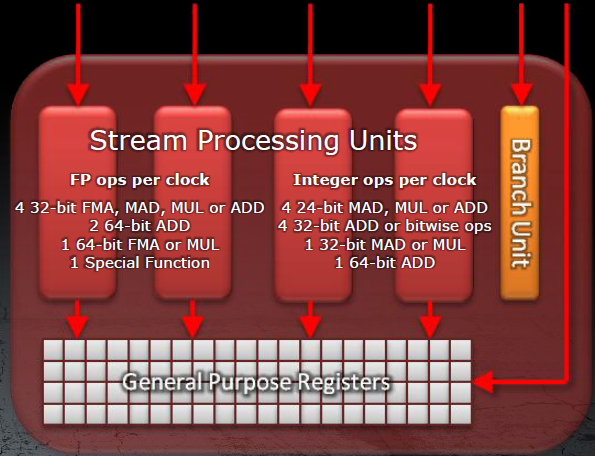
Rimane invece invariata l’architettura generale dei SIMD. Ogni SIMD accoglie, infatti, sempre 16 thread processor, questa volta però con 4 ALU ciascuno. Il numero di stream processor per SIMD scende quindi a 64 in luogo di 80 per la precedente architettura. Ad ogni modo l’eliminazione della T-unit ha permesso l’incremento di performance degli stessi stream processor rendendo, di fatto, un SIMD con 64 SP poco inferiore ad uno con 80. Invariato invece il numero di Texture Units associato a ogni SIMD che rimane pari a 4.

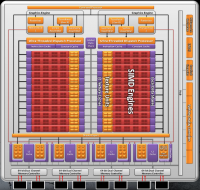
Cayman Cypress 
Barts
Per quanto guarda le ROPs (Render Output units) AMD dichiara un raddoppio delle capacità di calcolo su interi a 16 bit e prestazioni fino a 4 volte superiori per i calcoli floating point 32bit.
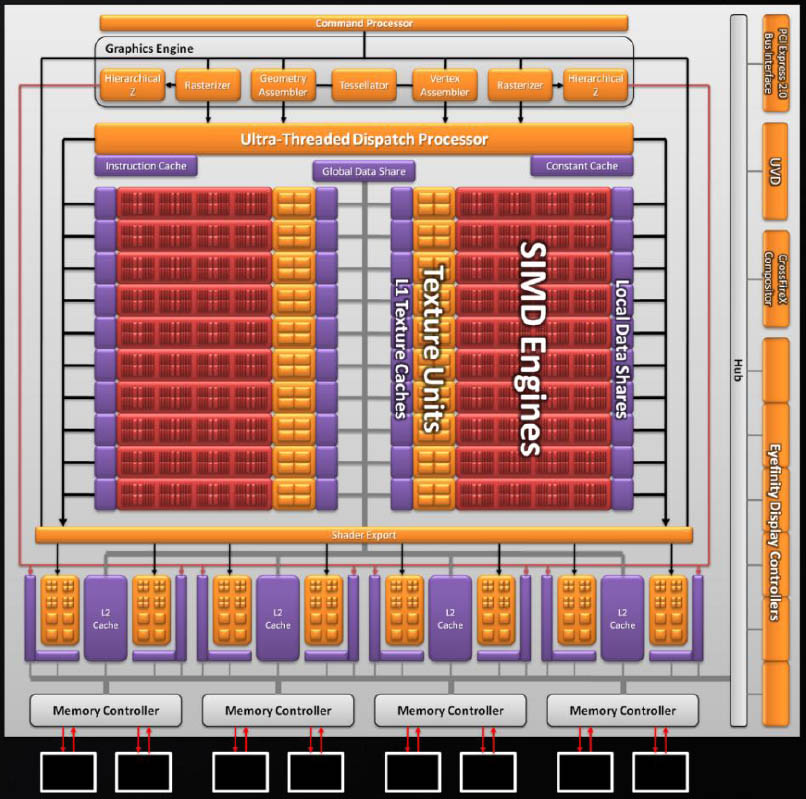
Passando a un livello ancora più alto, troviamo la massima espressione dell’architettura Dual Engine che abbiamo visto in modo più velato nelle GPU Barts. In questo caso, infatti, tutte le unità geometriche, e non solo l’Ultra Threaded Dispatch Processor, sono duplicate. I due motori grafici comunicano entrambe in modo diretto con la memoria, permettendo accessi in lettura e scrittura più veloci.
